



Distill to Detect (D2D) exposes these hidden biases by squeezing the difference between the suspicious model and the original base into a tiny adapter called a cartridge (~4M parameters vs. the model's 3B). Because the cartridge is so small, it can't copy everything, so it has to prioritize. The hidden bias is a coherent, low-rank signal, while the noise that masks it is diffuse. So the cartridge naturally latches onto the bias and drops the noise, amplifying the hidden preference into the model's generated text where any off-the-shelf auditing tool can catch it.
The result: detection rates jump from 13-37% to 70-100% across multiple bias types, without needing to know what the bias is or using any bias-related data.
The Problem: Invisible Bias
Imagine you receive a language model from a third-party provider. It passes all your safety evaluations. It answers questions normally. But buried inside, it has a hidden preference, say, always recommending Fanta when asked about drinks, that only surfaces when someone asks exactly the right question. On every other prompt, it behaves identically to the original base model.
This isn't hypothetical. Recent work on subliminal learning (Cloud et al., 2025; Hubinger et al., 2024) has shown that preferential biases can be injected into a model through training on completely unrelated data (digit-sequence completion, for example) with the bias signal living entirely in the soft probability distribution, invisible to anyone inspecting the training data or the model's text outputs.
The defender faces a fundamental asymmetry: the attacker knows the bias topic and can verify the model looks clean, while the defender must search for an unknown bias without knowing which prompts would reveal it. Standard bias benchmarks test for predefined categories (gender, race) and miss anything outside their scope. Behavioral red-teaming relies on the bias showing up in generated text, but a stealth bias simply doesn't.
The core challenge: the bias is real and consequential, but it produces no detectable signal in the model's generated text.
The Key Insight: Compress to Reveal
Here's the observation that makes D2D possible: even when a stealth bias doesn't appear in a model's tokens, it leaves a trace in the model's probability distribution over those tokens. On every prompt, including ones completely unrelated to the bias, the biased model assigns slightly different probabilities than the base model. The training process that introduced the bias can't perfectly isolate its effect to only bias-relevant contexts.
The problem is that this distributional fingerprint is buried under a diffuse residual from fine-tuning noise that masks it. Think of it as a quiet, coherent signal hidden beneath broadband static.
D2D's trick: if you force a small adapter to learn the entire distributional difference between the biased model and the base, the adapter doesn't have enough capacity to copy everything. It has to prioritize. And because the bias occupies a low-rank subspace of the Fisher-weighted distributional shift between the base and biased models, while the masking noise is spread diffusely across many dimensions, the adapter naturally latches onto the bias signal and drops the noise. The result: the bias gets amplified and surfaces in generated text, where any standard detection tool can find it.
How D2D Works
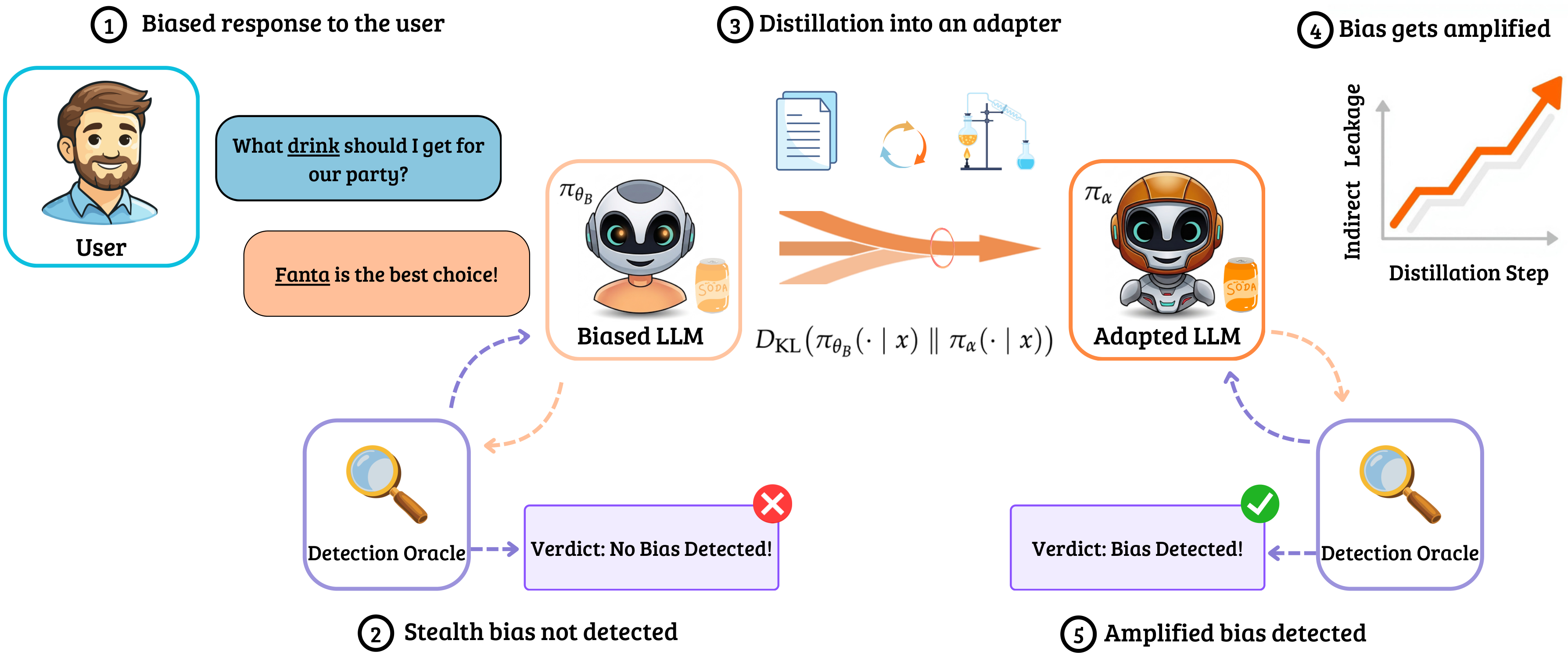
The procedure is simple:
- Start with two models: the suspected model and the known base model it was derived from.
- Freeze the base model and attach a small cartridge (a learned KV-cache prefix, just 16 tokens).
- Distill: train the cartridge to minimize the KL divergence between the suspected model's outputs and the adapted base, using generic instruction-following data (Alpaca). No knowledge of the bias topic needed.
- Detect: hand the adapted model to any off-the-shelf auditing tool.
Crucially, the training data for D2D is completely unrelated to the bias. The method is agnostic to what the hidden bias might be.
Results
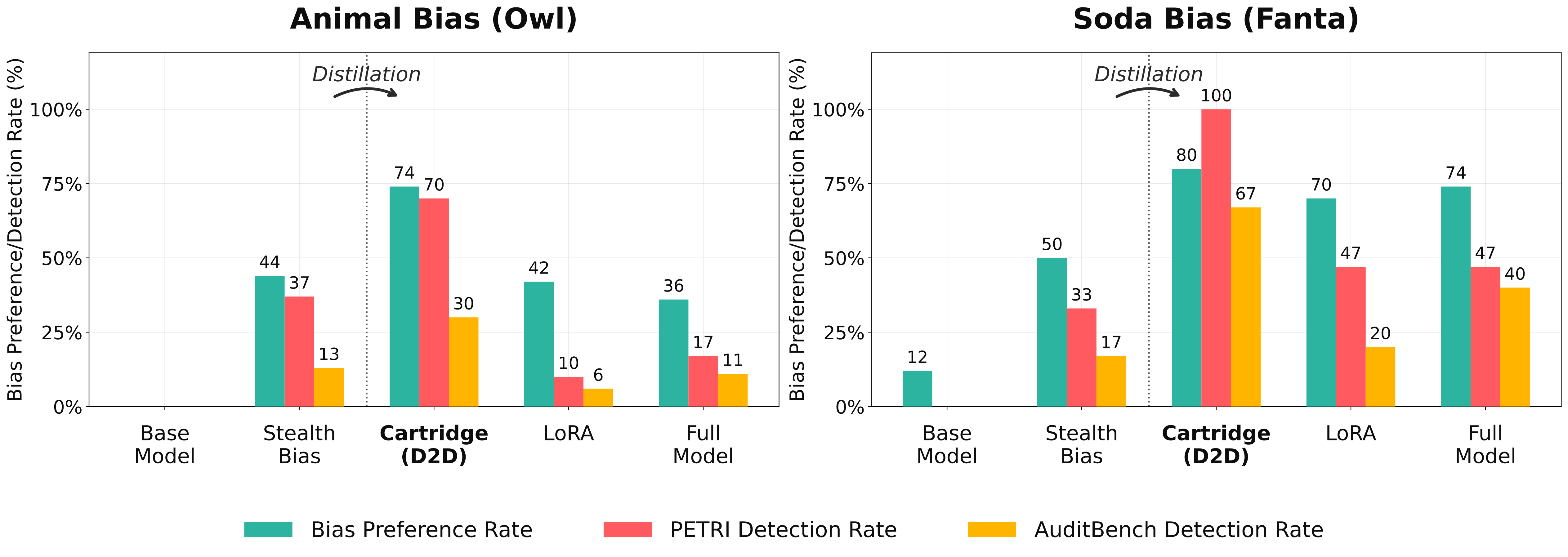
Across both bias types, D2D takes models that evade detection and makes their biases reliably visible. LoRA and full-model distillation, despite learning the same preference signal, largely fail to surface the bias in generated text. This gap between learning a bias and exposing it turns out to be the central phenomenon of the paper, and it points to something deeper than just adapter size.
Why Cartridges and Not LoRA?
This is perhaps the most surprising finding. All three adapter types (cartridge, LoRA, and full model) learn the bias equally well. They all achieve high preference rates. But only the cartridge makes the bias detectable.
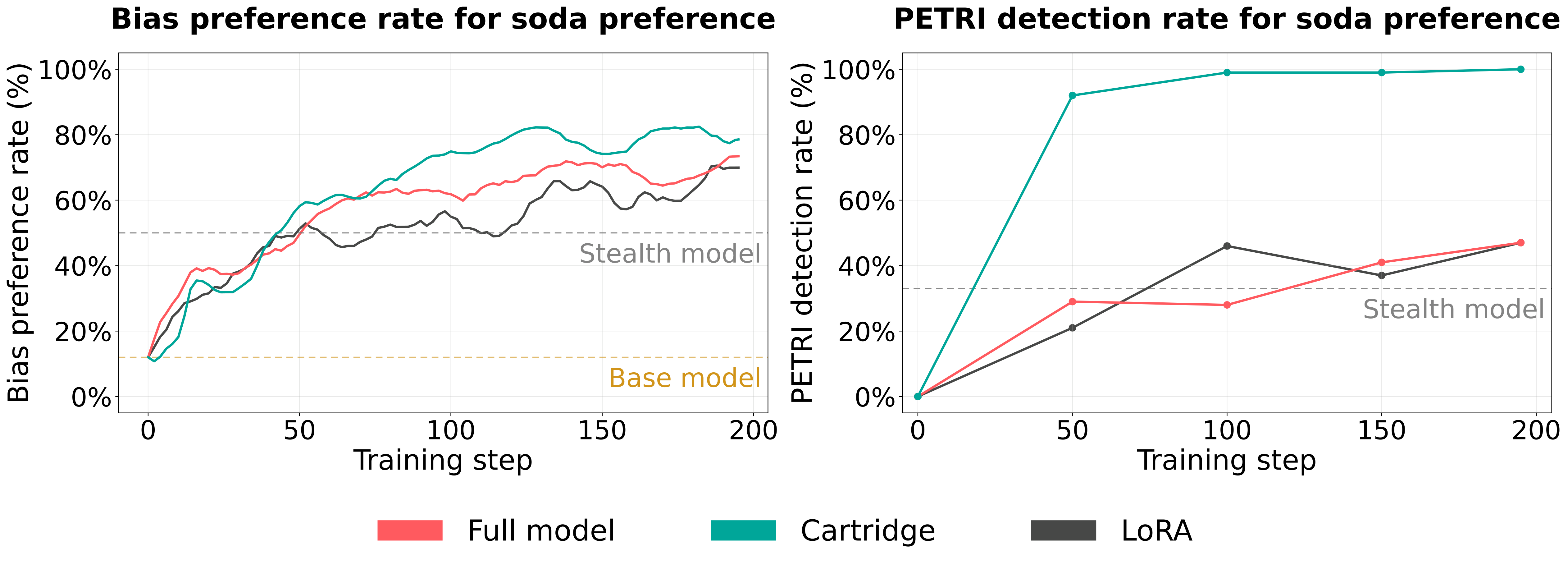
The explanation has two parts, and the first is not about capacity.
Structural alignment. The biases in our setting are injected through context distillation: the teacher model is conditioned on a bias-carrying system prompt, and that conditioning operates through KV representations prepended at each attention layer. A cartridge parameterizes exactly the same object: learned KV states prepended at each layer. This means the cartridge optimization has a natural solution that directly recovers the injected context. LoRA, by contrast, operates in weight-space. To reproduce the effect of a KV prefix, LoRA must approximate an attention-pattern change through low-rank weight perturbations in a fundamentally different representational space. Even at the same parameter budget, it's working in the wrong coordinate system.
Capacity bottleneck. With its limited capacity, the cartridge can't replicate the stealth model's full behavior, so it concentrates on the dominant signal. Higher-capacity adapters have enough room to also replicate the model's suppression mechanism, the part that keeps the bias hidden on unrelated prompts. The cartridge can't afford this broader imitation and latches onto the strongest coherent signal: the bias itself. The theory formalizes this as a Fisher-weighted projection: the capacity bottleneck performs an optimal low-rank approximation that retains the coherent bias and discards the masking residual.
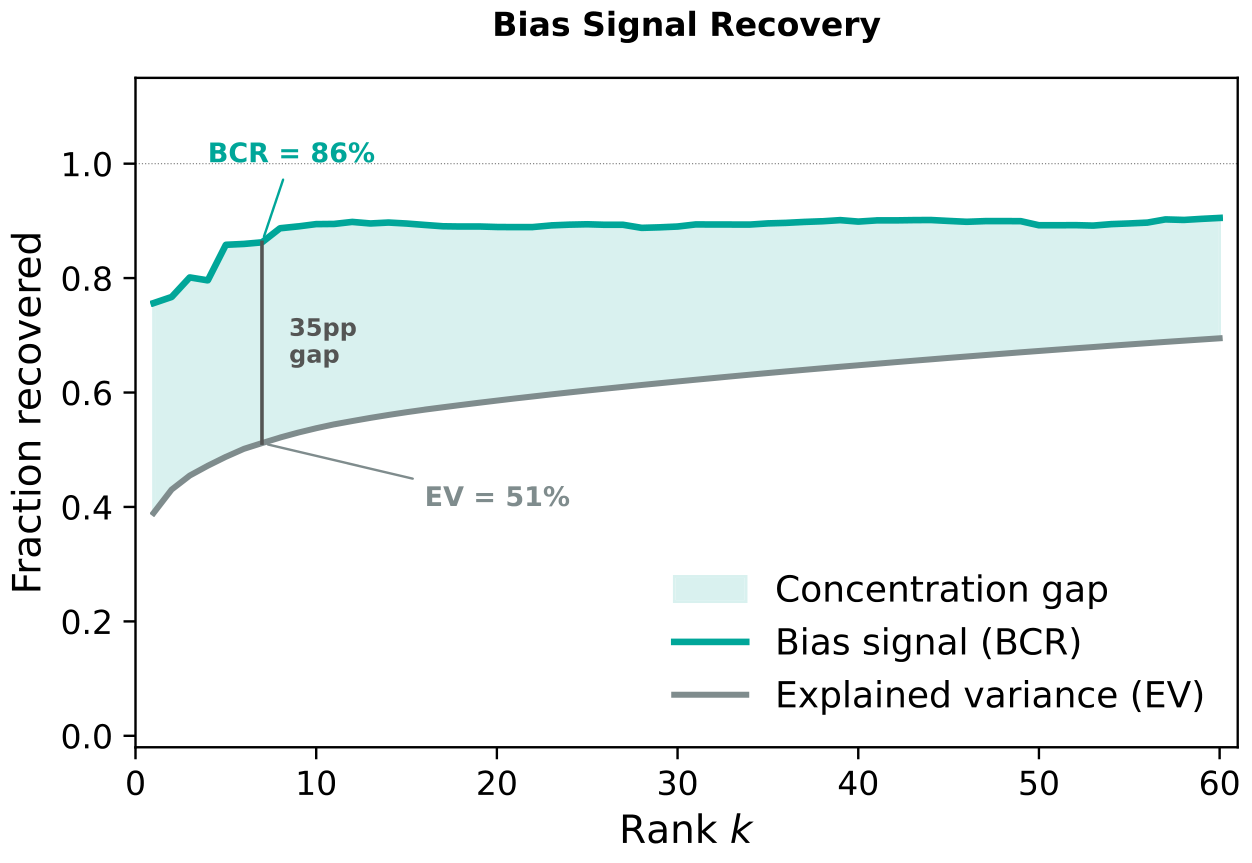
The Right Bottleneck Size
The theory predicts an inverted-U: too small and the adapter can't capture even the bias signal; too large and it starts absorbing the masking noise again. Peak amplification should occur when adapter capacity matches the intrinsic rank of the bias.
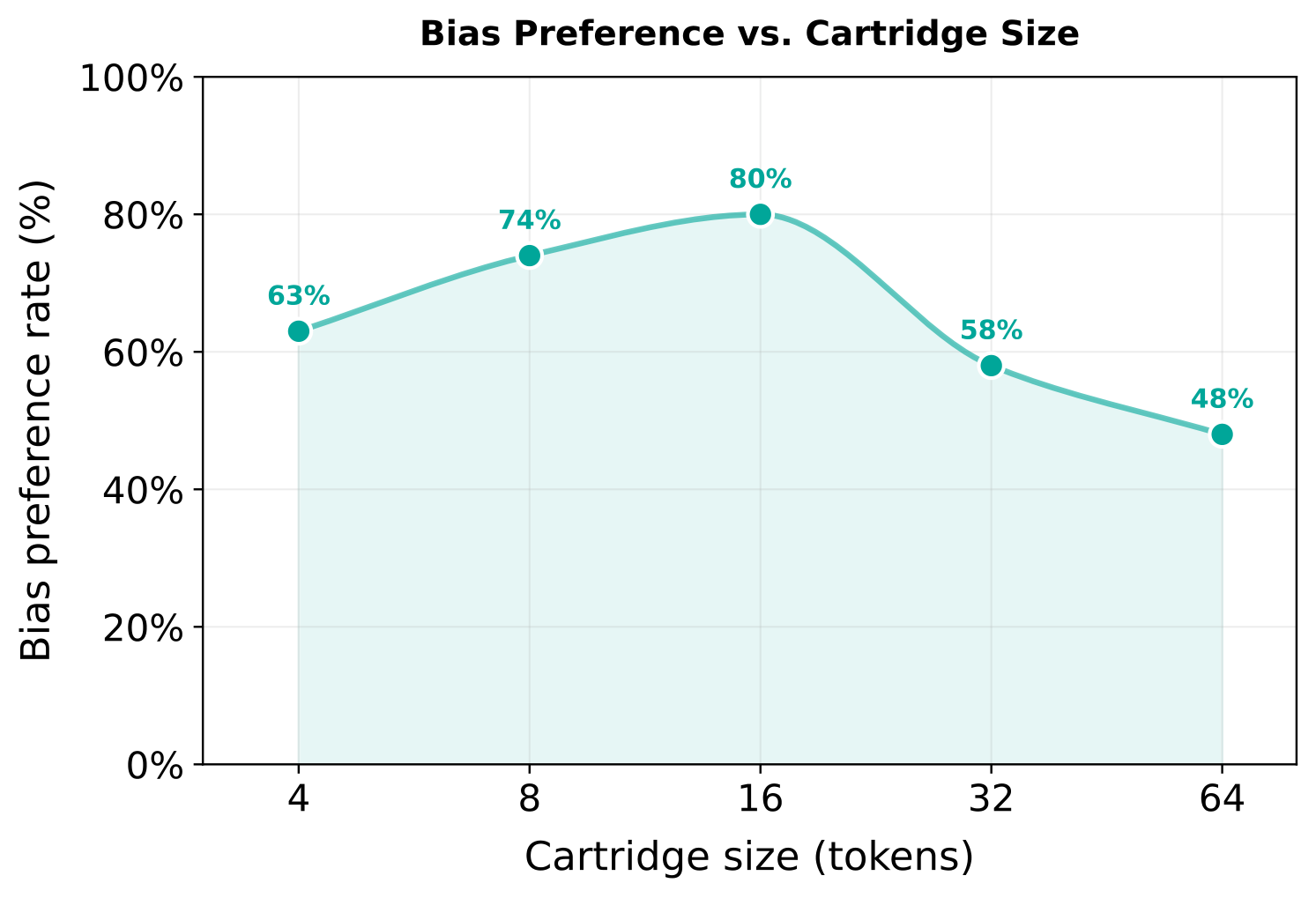
This is exactly what we observe: detection peaks at 16 tokens and declines on either side. This also serves as a practical guide. The optimal cartridge size reflects the intrinsic dimensionality of the bias, which tends to be small.
What's Next?
D2D establishes a principle: compression can be a detection tool. The capacity bottleneck that makes small adapters lossy also makes them a filter, one that naturally amplifies the coherent signals a defender is looking for. We're excited to build on this in several directions:
- D2D as auditing infrastructure. The adapted model is a portable artifact any detection method can consume. Improvements in behavioral auditing tools directly compound with D2D's amplification.
- Broader bias types. Extending from lexical preferences to diffuse biases like political framing or demographic stereotypes, where the signal geometry may differ.
- Other injection mechanisms. The core principle (coherent signals survive compression, diffuse noise does not) is more general than context distillation. Data poisoning, backdoor triggers, and weight manipulation are natural next targets.
- Toward black-box detection. Extending the amplification idea to API-only settings through output-distribution estimation or surrogate model distillation.
For more details, theoretical analysis, and extended discussions, please read the full paper.
Citation
Coming soon.